机房主机集中管理与监控主机的核心价值与实践
在当今数字化时代,数据中心机房是企业信息系统的核心命脉。机房内服务器、存储、网络设备等主机数量庞大且持续增长,其稳定、高效、安全的运行直接关系到业务连续性。因此,机房主机集中管理与监控已成为现代IT运维不可或缺的关键环节,而监控主机正是实现这一目标的核心枢纽与智能大脑。
一、 机房主机集中管理的核心内涵与挑战
机房主机集中管理,是指通过统一的技术平台与规范流程,对分散在机房内的各类计算、存储及网络资源进行整合式的监控、配置、部署、维护与优化。其核心目标在于:
- 提升运维效率:改变传统“人跑机房”的被动响应模式,实现远程、批量、自动化的操作,大幅降低人力成本与操作错误率。
- 保障系统稳定:通过7x24小时不间断的监控,提前预警潜在风险,快速定位并排除故障,最大限度减少业务中断时间。
- 优化资源利用:全面掌握主机资源(CPU、内存、磁盘、网络)的使用状况,为容量规划、性能调优和成本控制提供数据支撑。
- 强化安全合规:集中管理访问权限、操作日志和安全策略,满足审计与合规性要求。
面临的挑战主要包括:设备品牌型号异构、监控指标繁杂、海量告警噪声、虚拟化与云环境融合等。
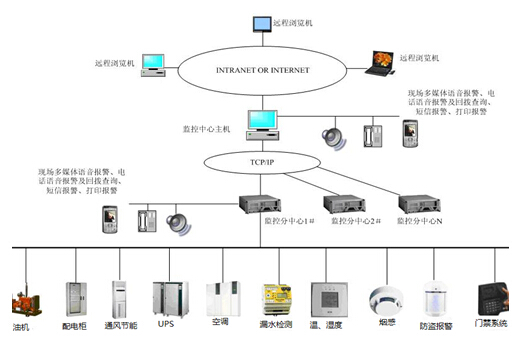
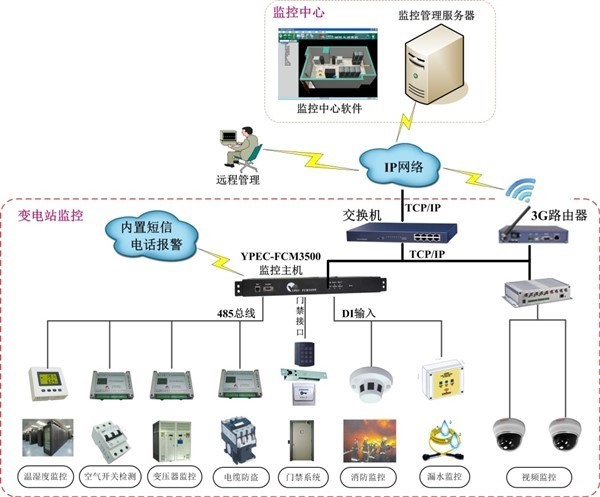
二、 监控主机:集中管理的“神经中枢”
监控主机(通常指部署了专业监控软件的专用服务器或高可用集群)是集中管理体系的执行核心。它并非简单的数据收集器,而是一个集数据采集、处理、分析、展示与联动于一体的智能平台。
其主要功能模块包括:
- 自动发现与资产管理:自动扫描网络,识别并录入机房内所有IP设备,建立动态更新的资产清单,记录主机配置信息。
- 多维度数据采集:
- Agent方式:在被监控主机上安装轻量级代理,采集深度系统指标(如进程、日志、性能计数器)。
- 无Agent方式:通过SNMP、WMI、SSH、IPMI等标准协议,获取基础运行状态、硬件健康信息(如温度、风扇转速、电源状态)。
- 日志采集:集中收集和分析系统、应用及安全日志。
- 实时监控与可视化:
- 性能监控:以图表形式实时展示CPU使用率、内存占用、磁盘I/O、网络流量等关键指标。
- 状态监控:监控主机、服务、端口、URL等的可用性。
- 拓扑视图:动态生成网络拓扑图,直观展现设备间关联与状态。
- 智能告警与事件管理:
- 用户可自定义阈值和告警规则(如CPU持续5分钟超过90%)。
- 实现告警分级(紧急、重要、警告)、去重、压缩和升级。
- 支持通过邮件、短信、微信、钉钉等多种渠道通知相关人员。
- 报表分析与容量规划:定期生成性能、可用性、趋势分析报表,帮助管理员洞察历史规律,预测未来资源需求,实现前瞻性管理。
- 自动化响应与联动:高级监控系统可与运维自动化工具(如Ansible, SaltStack)或ITSM流程对接,实现“监控-诊断-修复”的闭环,例如自动重启异常服务、扩容磁盘等。
三、 实践部署的关键考量
构建一个高效的机房主机集中监控体系,需要关注以下几点:
- 架构设计:根据机房规模选择合适架构。中小型机房可采用单服务器部署;大型或分布式机房应采用分布式、可水平扩展的架构,并确保监控主机自身的高可用性(如主备集群)。
- 监控策略制定:明确“监控什么”和“如何监控”。避免过度监控导致资源浪费和告警疲劳,聚焦于与业务相关的核心指标。建立分级的监控策略。
- 网络与安全:确保监控网络通道的畅通与安全,特别是在跨越防火墙或不同网段时。严格管理监控系统的访问权限,加密敏感数据的传输与存储。
- 选型与集成:市场上有Zabbix、Nagios、Prometheus(结合Grafana)等开源方案,以及SolarWinds、Dynatrace、睿象云等商业产品。选型需综合考虑功能、性能、易用性、扩展性、社区支持及成本,并评估其与现有IT环境的集成能力。
四、 未来发展趋势
随着云计算、容器化和人工智能技术的普及,机房主机监控也在向更智能、更云原生的方向演进:
- AIops智能运维:引入机器学习算法,实现异常检测、根因分析、告警预测,从“人工排查”走向“智能诊断”。
- 云原生与容器监控:深度支持Kubernetes等平台,监控Pod、Service、Node及微服务链路的健康状况。
- 一体化可观测性:将监控(Metrics)、日志(Logs)与链路追踪(Traces)数据深度融合,提供端到端的业务洞察。
机房主机集中管理是企业IT运维从粗放走向精细、从被动走向主动的必由之路。 一个功能强大、稳定可靠的监控主机系统,如同为机房配备了一位不知疲倦的“超级管理员”,它不仅是故障的“吹哨人”,更是性能优化与业务保障的“智慧军师”,为数字业务的平稳高效运行筑牢坚实底座。
如若转载,请注明出处:http://www.grqbw.com/product/8.html
更新时间:2026-06-06 13:47:19